一文读懂“监控”与“可观测性”的区别

2018年,可观测性(Observability)被引入IT领域,CNCF-Landscape率先出现了Observability的分组。自此以后,“可观测性”逐渐取代“监控”,成为云原生技术领域最热门的话题之一。
(图片来源:CNCF-Landscape)
云原生驱动,从“监控”到“可观测性”
- 传统监控须追随数字化转型脚步
Gartner认为数字化转型以业务为中心,服务和用户体验是关键目标。而IT监控以系统可用为中心,仅关注系统可用性指标对于转型中的企业而言是一场灾难。到2023年,依赖于“正常运行时间”指标的监控实践将抑制90%的转型计划。过去,运维部门围绕着系统的可用性开展工作,故障诊断是第一要务;现在,一切以业务发展为导向,运维部门在保障应用可用的同时,更须衡量性能对业务以及最终用户所产生的影响,保障用户体验,为数字化业务赋能。
- 云原生为传统监控带来挑战
随着企业从单体架构发展到分布式架构,采用微服务、容器等部署方式,IT基础设施变得愈发不可控。除此以外,还有许多企业开始采用Serverless等更符合云原生环境的技术方式,监控无法再单独以运维的视角、被动地解决故障为目标,而要追随IT架构的改变、云原生技术的实践,融入开发与业务部门的视角,具备比原有监控更广泛、更主动的能力,这种能力被称作“可观测性”。
“可观测性”究竟是什么?
- “监控”是“可观测性”能力的一部分
因此,“监控”虽是“可观测性”能力的一部分,但研发的介入使得“可观测性”从过去的被动监控转向主动的发现与分析。
- “主动发现”是“可观测性”能力的关键
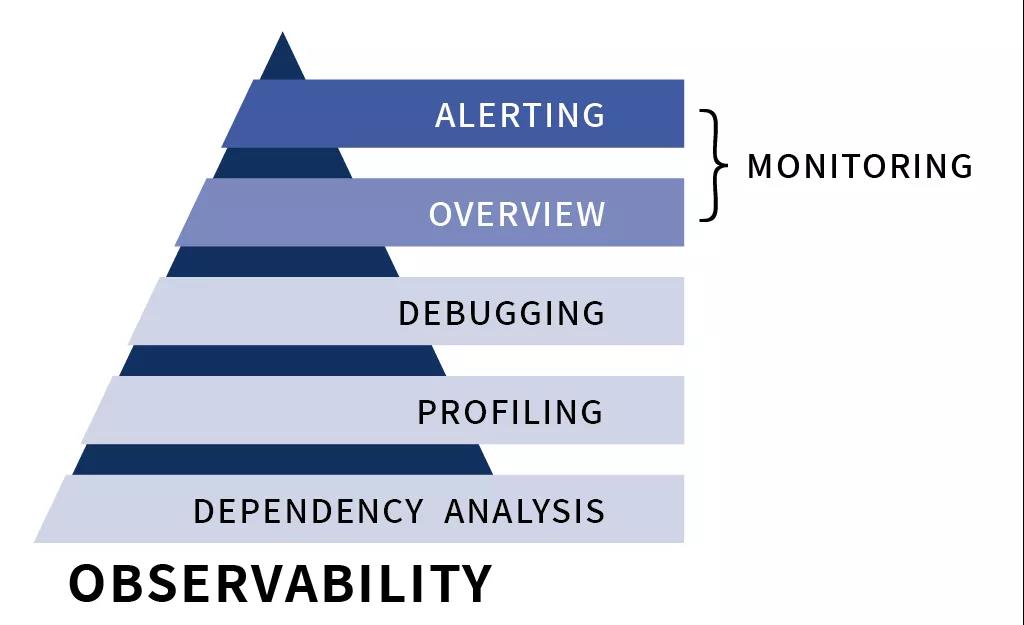
(“可观测性”能力与“监控”)
- 排错(Degugging),即运用数据和信息去诊断故障出现的原因;
- 剖析(Profiling),即运用数据和信息进行性能分析;
- 依赖分析(Dependency Analysis),即运用数据信息厘清系统之前的模块,并进行关联分析。
这三部分同样存在严谨的逻辑关系:首先,无论是否发生告警,运用主动发现能力都能对系统运行情况进行诊断,通过指标呈现系统运行的实时状态;其次,一旦发现异常,逐层下钻,进行性能分析,调取详细信息,建立深入洞察;再次,调取模块与模块间的交互状态,通过链路追踪构建“上帝视角”。主动发现能力的目的并不是为了告警与排障,而是通过获取最全面的数据与信息,构建对系统、应用架构最深入的认知,而这种认知可以帮助我们提前预测与防范故障的发生。
- 如何运用“可观测性”能力?
- 日志信息(logs),即记录处理的离散事件。它展现的是应用运行而产生的信息或者程序在执行任务过程中产生信息,可以详细解释系统的运行状态。日志数据很丰富,但是不做进一步处理就变得难以理解。
- 追踪链路(trace),处理请求范围内的信息,可以绑定到系统中单个事务对象的生命周期的任何数据。Trace在很大程度上可以帮助人们了解请求的生命周期中系统的哪些组件减慢了响应等。
- 指标信息(metrics)。Metrics作为可聚合性数据,通常为一段时间内可度量的数据指标,透过其可以观察系统的状态与趋势。
理想状态下,我们一般通过可观测性能力整体观察系统的健康度,借助“主动发现”的三个层级,提取应用系统的实时指标,调取相关的日志信息,最后通过发现应用模块之间的关联,实现全链路追踪,进而构建对整个应用体系的审视与洞察。作为全球最大的云原生开源社区,CNCF推出的Open Telemetry以期实现理想状态下的大一统:统一Logs、Trace、Metrics三种数据协议标准,使用一个 Agent 完成所有可观测性数据的采集和传输,适配众多云厂商,兼容CNCF上众多的开源与商业项目···但是至今未有厂商或开源项目可以统一Open Telemetry后端,三种数据源的统一存储、展示与关联分析仍面临极大挑战,而解决以上问题的前提,仍然是统一数据源(数据格式)。
从迈入云原生的那一刻起,技术更新迭代的速度明显加快。而一项技术的发展总会带动相关技术的进步,从“监控”到“可观测性”,更丰富的技术、组织、内容融入其中,建构出对整个应用更宏大的认知。而这种认知如果以统一的数据信息为依托,将会大大提高“主动发现”的能力,理想状态也终将成为现实。
关注天旦公众号
跟旦旦一起,
让运维稳定无忧,
运营做你所想。

